
Dieser Text ist Teil der September-Folge meines monatlichen Newsletters „Digitale Notizen“, den man hier kostenlos abonnieren kann. Um ihn besser zu verstehen, empfehle ich den Text „Das bin ja ich“ aus dem vergangenen Jahr. (Fotos oben, Screenshots und unsplash.)
„Nur sammeln. Immer sammeln. Eindrücke, Wissen, Lektüre, Gesehenes, Alles. Und nicht fragen wozu und warum. Ob ein Buch daraus wird oder Memoiren oder gar nichts. Nicht fragen, nur sammeln.
Was haben Victor Klemperer und das Microsoft Projekt „Recall“ gemeinsam?
Sie helfen mir zu verstehen, wie KI meinen Beruf verändern wird. Sie eröffnen mir beide eine Perspektive auf die Dinge, die ich besser verstehen und verändern sollte. Und sie helfen mir, digitales Lesen zu lernen.

Das Einstiegszitat stammt von Victor Klemperer, dessen Tagebücher der Deutschlandfunk in diesem Sommer als Hörspiel aufbereitet hat. Genau diese Tagebücher und das akribische Notieren von Beobachtungen erinnern mich an das Angebot, das Microsoft mit seinem Projekt „Recall“ plant gerade verschoben hat: „Nur sammeln. Immer sammeln“ heißt für Microsoft, sie wollen einen KI-Rechner auf den Markt bringen, der ständig Screenshots dessen macht, was Nutzer:innen an ihm tun. „Eindrücke, Wissen, Lektüre, Gesehenes, Alles.“ Alles, was hilft, ein fotografisches Gedächtnis zu befüllen.
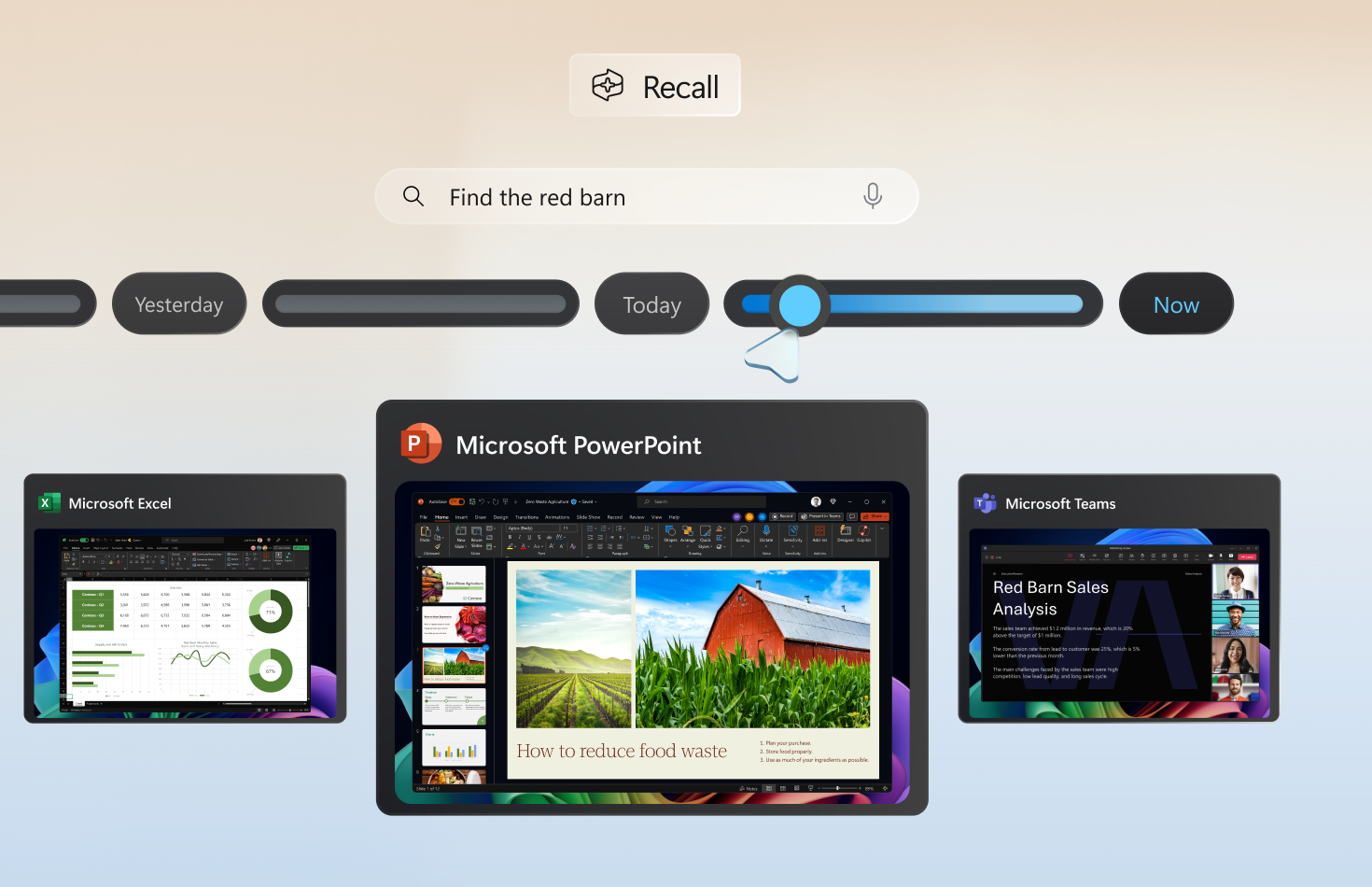
Denn: „When logged into your Copilot+ PC, you can easily retrace your steps visually using Recall to find things from apps, websites, images and documents that you’ve seen, operating like your own virtual and completely private “photographic memory.”„
„Und nicht fragen wozu und warum. Nicht fragen, nur sammeln.“
Was die Frage aufwirft: Warum sind Microsoft und Klemperer so am Sammeln interessiert? Wie kann es sein, dass ein Tech-Gigant und ein Groß-Intellektueller so vergleichbare Begeisterung fürs Sammeln zeigen?
Die Antwort lässt sich mit der Informatiker-Phrase „GIGO“ erfassen. Das Akronym steht für „Garbage in, Garbage out“ und beschreibt das Prinzip, dass die Ausgangsdaten mit hoher Wahrscheinlichkeit den Wert der Ausgabedaten beeinflussen. Allgemeiner formuliert: eine Maschine kann nur auf Basis dessen Ergebnisse liefern, was ihr zur Verfügung steht.
Womit wir beim digitalen Lesen angekommen sind.
Seit ich im vergangenen Herbst in den KI-Spiegel schaute beschäftigt mich die Frage: Wie werde ich diese neue KI-Schreibmaschine benutzen können? Welche Fähigkeiten muss ich lernen, um dieses Instrument in meine Arbeit zu integrieren?
Und durch Victor Klemperer und Microsoft Recall habe ich gelernt: Um mit Hilfe von KI schreiben zu können, muss ich den Input verbessern, der in eine KI hineingeht und die Basis für die Intelligenz bildete, die mir hier künstlich helfen soll. Damit mir der KI-Spiegel mehr zeigt als den Durchschnitt, den er aus allen verfügbaren Internet-Daten hochgerechnet hat, muss eine Person vor ihn treten, die dort auch sichtbar wird. In Abwandlung des GIGO-Akronyms will ich von der YIYO-Vorgabe sprechen: „You in, you out“ (dass in diesem Satz eine Doppeldeutigkeit steckt, ist Absicht. Die Frage, ob und wie wir beim Blick in diesen KI-Spiegel verloren gehen, trage ich bei all dem immer mit).
Wenn ich will, dass die KI auf Daten zugreift, die auf mich zugeschnitten sind und mir helfen, muss ich ihr Zugang zu meinen Daten gegeben – bzw. ich muss diese Daten erstmal selber haben. Was mich zurück zu Klemperer führt: Wo sind denn eigentlich all meine digitalen Notizen (sic!)? Völlig unabhängig von Technologie-Anbietern oder Buch-Regalen – wo finde ich „Eindrücke, Wissen, Lektüre, Gesehenes, Alles“?
KI vernünftig zu nutzen, heißt Eindrücke, Wissen, Lektüre, Gesehenes, Alles zu sammeln. Denn nur, wenn ich all das gesammelt habe, kann eine KI daraus lernen, kann es für mich nach Mustern durchsuchen, die ich nicht kenne oder bisher nur unscharf sehe.
Google versucht genau das mit dem Angebot NotebookLM zu realisieren – ein Ort, an dem alles gebündelt wird, was ich an Eindrücken, Wissen, Lektüren und Gesehenem sammeln will. Dieses digitale Notizbuch geht nicht ganz so weit wie Microsoft Recall, aber es ist schon erstaunlich umfassend. Um das Projekt zu entwickeln, hat Google einen der renommiertesten amerikanischen Sachbuchautoren gewonnen: Steven Johnson berichtet auf seinem Medium-Blog, warum er diese digitale Schreibmaschine entwickeln will und warum er das Ergebnis super findet.
Ich persönlich teste seit ein paar Wochen das Angebot von Readwise (und suche dort noch immer nach einer Möglichkeit, meine tolino-Lektüre zu integrieren). Aber digitales Lesen lernen wird im ersten Schritt nicht auf der individuellen Ebene gelingen. Es braucht eine strukturelle Lösung. Es wird Anbieter geben, die digitales Lesen technisch ermöglichen – vielleicht sogar ohne, dass sie selbst Inhalte erstellen. Spotify hat im Bereich der Musik gezeigt, wie dieses Prinzip funktioniert.
Mich wundert, dass hier nicht mehr Aufbruchstimmung herrscht. Denn wer genau hinschaut, sieht: Im Bereich des digitalen Lesens gibt es ein erstaunliches Potenzial. Mit Blick auf die Statistik zum Anteil von eBooks am deutschen Buchmarkt kann man sagen: Wir lesen in diesem Land noch gar nicht digital! Bei 6,1 Prozent lag der Umsatzanteil von eBooks im Publikumsmarkt in Deutschland im Jahr 2023. Das ist erstaunlich wenig und kaum mehr als im Jahr davor.
Anders formuliert: Bei der Frage wie KI den Beruf derjenigen verändert, die Inhalte erstellen, geht es weniger um Ego-Fragen, als vielmehr um die Hoheit über Daten. Wer sammelt, was Klemperer und Microsoft sammeln wollen? Denn nur wer Inhalte sammelt, wird Inhalte erstellen können. Daran hat KI nichts geändert, das Prinzip aber kaum vorstellbar erweitert.
Der Text ist Teil meines monatlichen Newsletters Digitale Notizen, den du hier bestellen solltest, wenn du dich für die Veränderung durch KI interessierst. Zu dem Thema habe ich bereits über die „Lösung für das KI-Problem“ geschrieben und in den KI-Spiegel geschaut. Außerdem habe ich KI-Expert:innen gefragt, was ich über ihr Thema wissen muss.